タダです.
バッチ処理の中でこれまでは AWS Batch 1台のコンテナで完結していた処理があったのですが,処理時間が非常に長くかかってしまう部分があり,その処理を外出しして並列処理ができるよう Step Functions の Map を使ってみました.この記事で要点をまとめていければと思います.
docs.aws.amazon.com
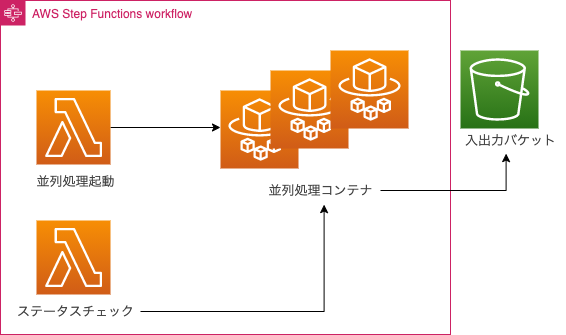
構成イメージ
構成イメージは下記のものになります.ECS Fargate の起動とパラメーターを渡す Lambda と Map を使って多数の ECS Fargate が起動するため各コンテナのジョブステータスをポーリングする Lambda が並列処理の成功と失敗を判定します.Fargate は起動後インプットファイルの取得とアウトプットの出力で S3 バケットを使うような動きをします.なお,Fargate は Fargate Spot で起動させています.
Step Functions の 定義
Step Functions の定義は下記のような ASL を設定しました.最初の Lambda で ECS Fargate を起動して次の Lambda で ECS Fargate のタスク実行状況をポーリングして成功か失敗かを判定する動作をします.60秒待機した後,再度ポーリングし,ジョブが終了していた場合,成功か失敗かを判定するような形です.
ASL 定義
{
"Comment": "Processing ECS Fargate",
"StartAt": "test",
"States": {
"test": {
"Type": "Map",
"End": true,
"Iterator": {
"StartAt": "Lambda Invoke",
"States": {
"Lambda Invoke": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:run-sfn-execute"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"Next": "status Lambda Invoke"
},
"status Lambda Invoke": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"ResultPath": "$.status",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:job-polling"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"Next": "Job Complete Check"
},
"Job Complete Check": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.status.Payload",
"StringEquals": "FAILLED",
"Next": "Notify Fail"
},
{
"Variable": "$.status.Payload",
"StringEquals": "SUCCEEDED",
"Next": "Notify Success"
}
],
"Default": "Wait 60 Seconds"
},
"Wait 60 Seconds": {
"Type": "Wait",
"Seconds": 60,
"Next": "status Lambda Invoke"
},
"Notify Success": {
"Type": "Pass",
"Result": "Success",
"End": true
},
"Notify Fail": {
"Type": "Pass",
"Result": "Fail",
"End": true
}
}
},
"ItemsPath": "$.parameter",
"Parameters": {
"hoge.$": "$.fuga",
"s3_bucket.$": "$.s3_bucket"
}
}
}
}
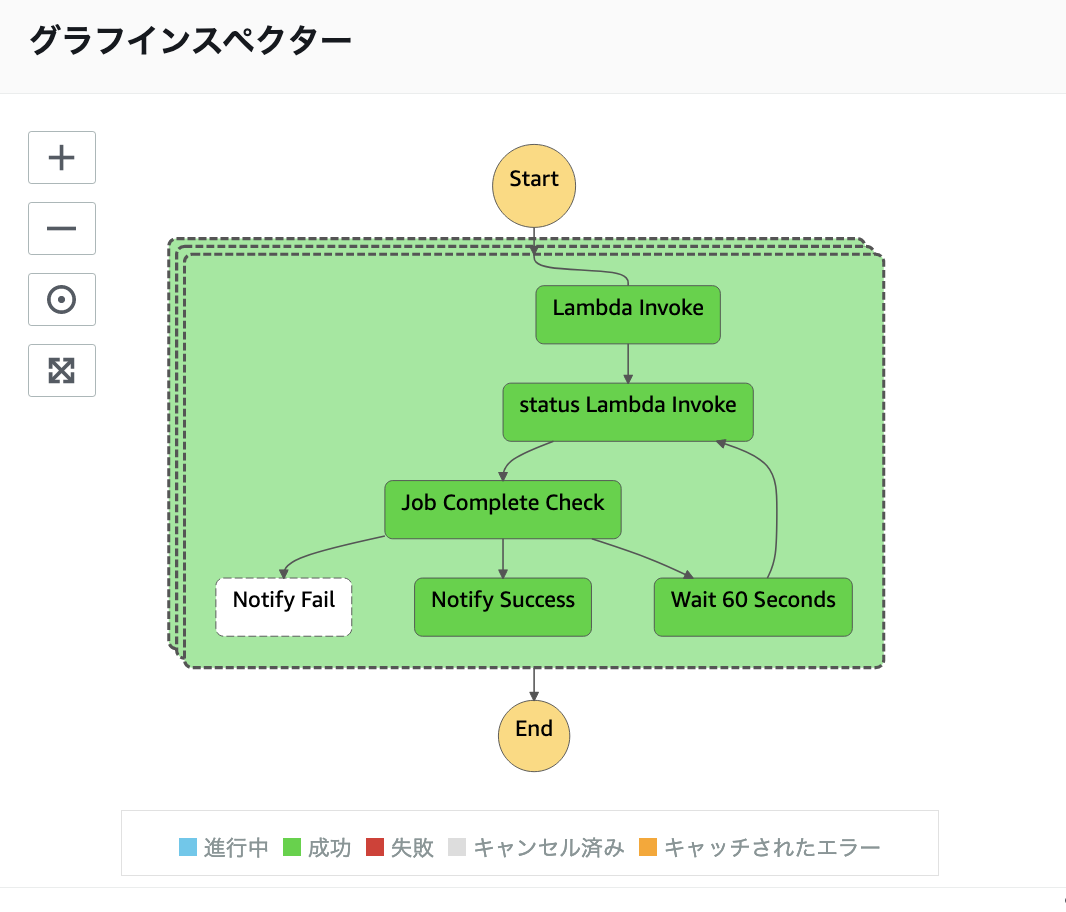
ワークフロー の処理結果確認
ワークフローの処理結果を確認すると以下のようなイメージで遷移し,期待通り動作していることを確認できました.
ワークフロー動作イメージ
注意点
一点だけ使っていて注意点があったのですが,Map の同時実行数が40以上を超えるとMaxConcurrencyの注記にもあるように一気に処理しない動作でした.ただ,一気に処理しきれない分も失敗にならず順次実行されるのでこの点を認識していれば問題ないのかなという感想を持ちました.
同時反復は制限される場合があります。この現象が発生すると、一部の反復は前の反復が完了するまで開始されません。入力配列に40項目を超えると、この問題が発生する可能性が高くなります。
docs.aws.amazon.com
40以上実行した場合の処理イメージ(第1弾の処理)

40以上実行した場合の処理イメージ(第2弾の処理)

40以上実行した場合の処理イメージ(最終結果)

まとめ
Step Functions の Map を使った ECS Fargate の並列処理ワークフロー を構築した話をまとめました.この変更により元々1台のサーバーで全処理をやろうとして4時間以上かかっていた処理だったのですが,外出しして約20分まで時間を短縮するのに寄与しており並列処理の選択肢として有効に効かせられたと思います.同じような課題にあたらている方の参考になれば嬉しいです!